
Deploying machine learning to the edge
The requirement for ubiquitous connectivity, security and the added latency are some of the challenges of cloud-based AI. These bottlenecks are resolved by transferring the AI algorithm from the cloud to an edge device. For AI-enabled smart applications that require real-time, secure-aware and low latency responses, Edge AI is the obvious choice forward.
Machine Learning (ML) at the Edge enables devices, ranging from autonomous cars to smart thermostats, to learn, adapt, and make decisions in real-time based on a large array of variables. NXP offers a comprehensive portfolio of Microcontrollers (MCUs) and Application Processors/ Microprocessors (MPUs) optimized for machine learning applications in automotive, smart industrial and IoT applications.
Through this article we highlight how NXP is accelerating ML across hardware and software enablement and turnkey solutions with the goal to provide innovative products and ecosystems that can compute-on-the-go while significantly shortening the time-to-market.
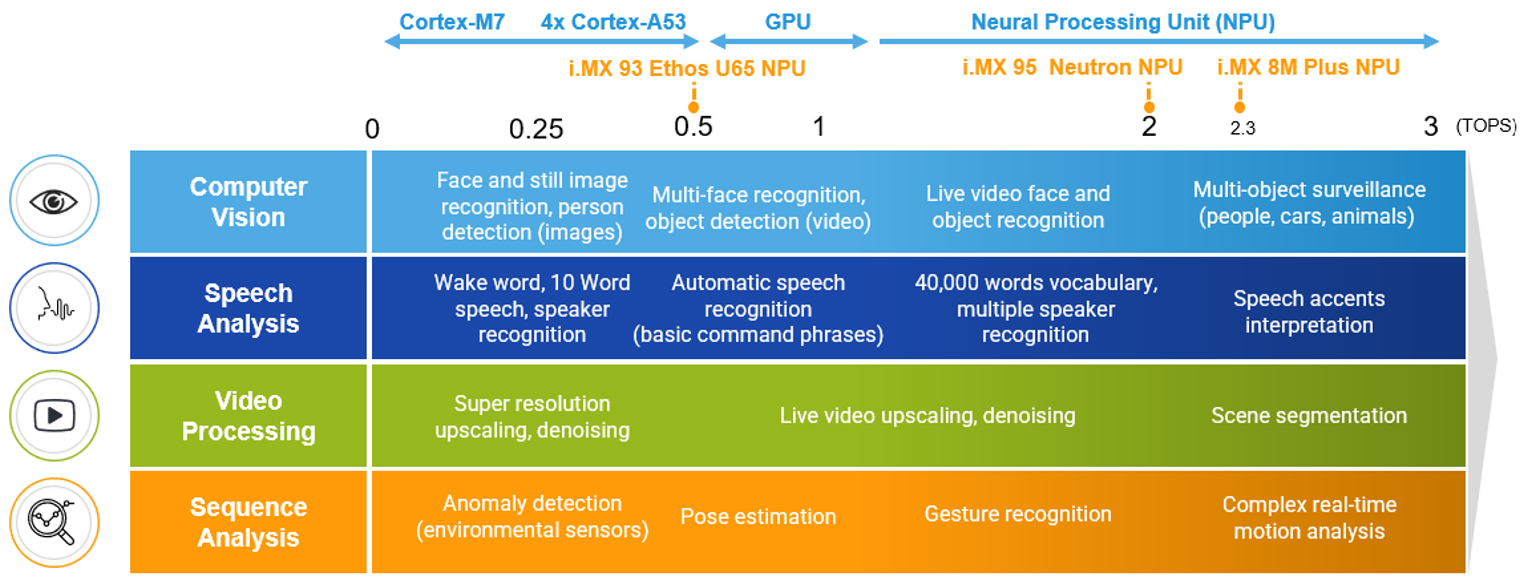
Figure 1: Machine Learning use cases and accelerators
The need for real-time data processing and more intuitive interaction has increased the need for accelerators built into processors. In order to reduce the processing load on the main cores for tasks like image/video rescaling or facial recognition, graphics processing units or GPUs, have been widely used. Nevertheless, some of the processing-intensive and power-hungry AI/ML applications, such gesture recognition and real-time object identification, are not always well suited for GPUs. This is where faster response times can be catered by a Neural Processing Unit (NPU).
At NXP, our goal is to create a portfolio that is future-proof by developing scalable hardware and software solutions that support seamless and optimal integration of AI/ML applications for customers. To obtain this high efficiency, tightly optimized hardware designs are necessary and software optimization that is tailored to the hardware architecture is equally critical. In this article we highlight:
- The NXP eIQ software which provides the necessary tools to train, optimize and deploy ML models on different devices, simplifying the design process and reducing error risks.
- Contextualizing the eIQ Neutron (NPU) and its architecture
- Overview of NXP’s MPU and MCU portfolio that support ML integration followed by an introduction of the flagship NPU-enabled MCU and MPU
- NXP’s Voicespot as an instance to integrate ML-enabled voice control software for small-footprint, low-power applications running without an accelerator core
1. eIQ® ML software development environment
The NXP® eIQ® ML software development environment enables the use of ML algorithms on NXP EdgeVerse™ microcontrollers and microprocessors, including i.MX RT crossover MCUs, and i.MX family application processors.
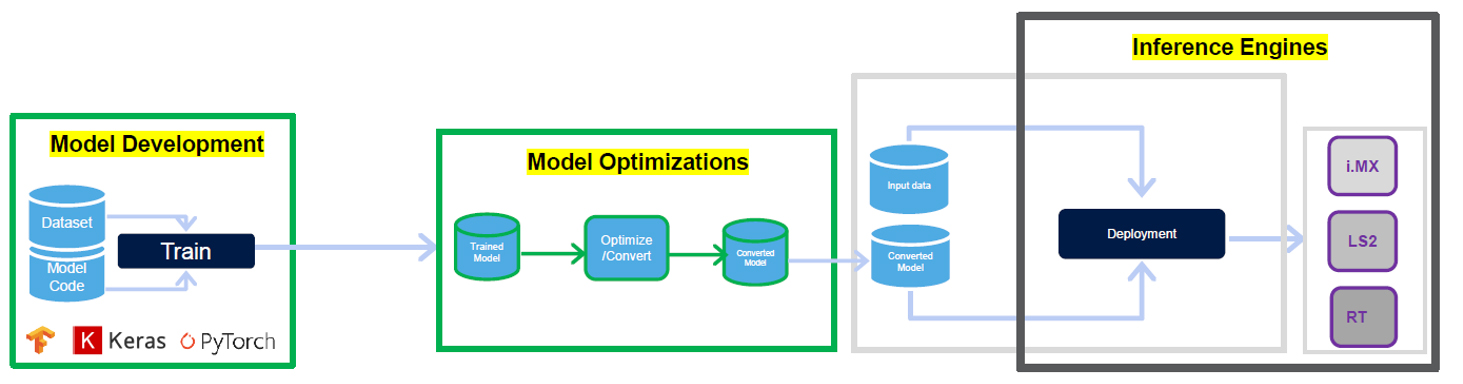
Figure 2: End-to-end ML deployment
For end-to-end ML deployment, the eIQ® ML software includes a ML workflow tool called eIQ® Toolkit, along with inference engines, neural network compilers, optimized libraries, and hardware abstraction layers that support TensorFlow Lite, Pythorch, ONNX, Glow, Arm® NN, etc. This software leverages open-source and proprietary technologies and is fully integrated into NXP’s MCUXpresso SDK and Linux® Yocto development environments, allowing users to develop complete system-level applications with ease.
Within the Toolkit, a variety of application examples that demonstrate how to integrate neural networks into voice, vision and sensor applications are included. The developer can choose whether to deploy their ML applications on Arm Cortex A, Cortex M and GPUs, or for high-end acceleration on the NPU unit of some of NXP’s flagship products – MCX N, i.MX 8M Plus, i.MX 93 and i.MX 95. Finally, It also includes methods that make the ML network more secure by addressing issues such as cloning, which is discussed in the last section here.
1.1 NXP eIQ® MACHINE LEARNING SOFTWARE — INFERENCE ENGINES BY CORE
Different inference engines are included as part of the eIQ® ML software development kit and serve as options for deploying trained Neural Network (NN), models. This allows users to bring their pre-trained deep learning models and use the eIQ® to architect their development to best fit the required use-case and project environment. This means scalability and ease to move or swap the software or hardware side to achieve a quick proof-of-concept within the eIQ® development environment.
These inference engines include:
- Arm NN INFERENCE ENGINE
- GLOW
- Arm CMSIS-NN
- TENSORFLOW LITE
- DeepViewRT™ RUNTIME
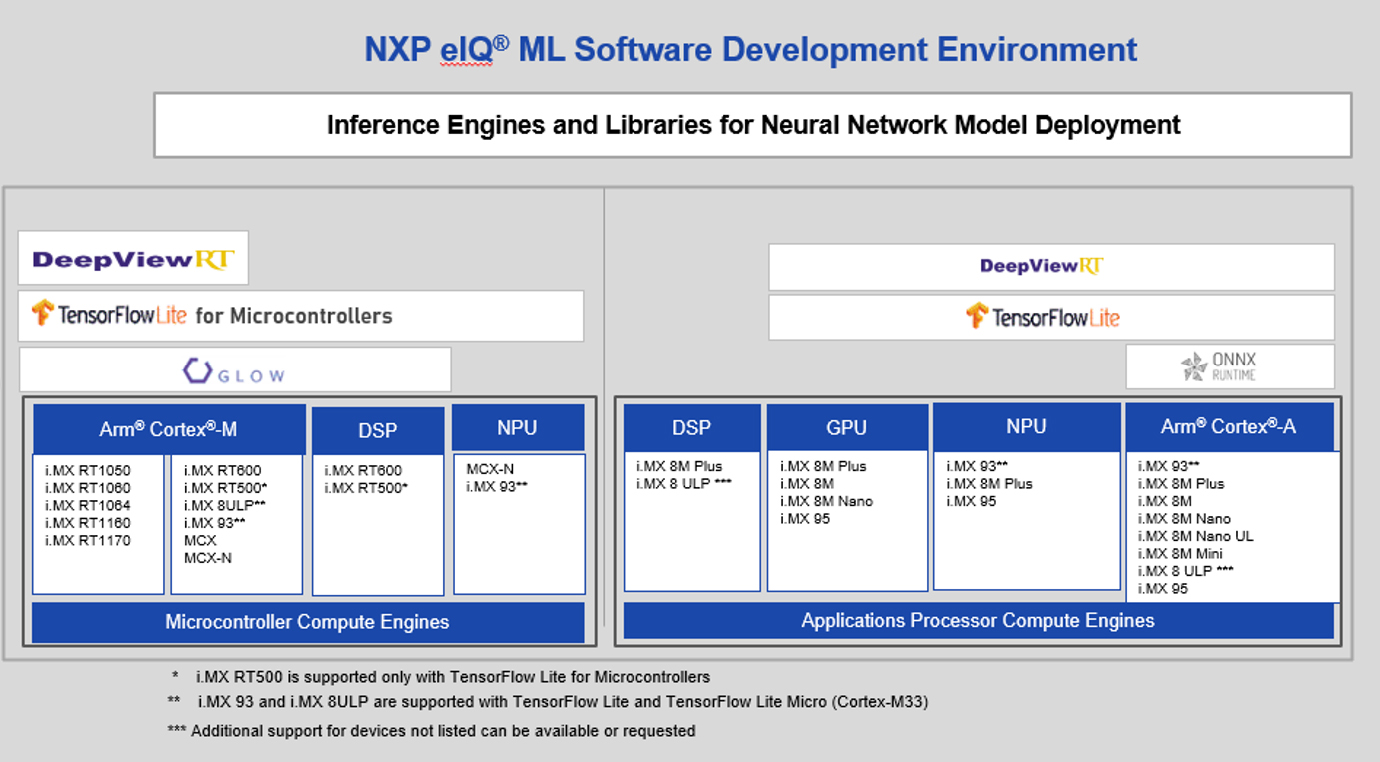
Figure 3: eIQ ML Software development environment inference engine options
1.2 Nvidia TAO Integration
NXP recently became the first semiconductor vendor to integrate NVIDIA TAO Toolkit APIs directly accessible from within NXP’s eIQ® tool. TAO toolkit has a vast repository pre-trained ML models. Customers can choose ML model closest to their application, fine-tune for their specific use-case, and then deploy it on NXP processors like i.MX and i.MX RT crossover. For this entire process, customers never have to leave NXP’s eIQ® environment. eIQ®, therefore becomes one-stop shop for model selection, fine-tuning, and then deployment.
1.3 Building ML to support a Secure, Connected Edge with IP Protection/Watermarking
The performance of models largely depends on the quality and quantity of their training data. However, the process of training- data collection, processing, organizing and storing it - can be time-consuming and expensive, making a trained ML model a high value intellectual property of the company that created it.
Given3 the broad attack surface of stealing ML models, it might be impossible to entirely prevent theft. If theft cannot be prevented beforehand, a legitimate model owner might want to react, at least, to the inflicted damage and claim copyright to take further steps. This can be achieved by watermarking a digital asset - the act of embedding identification information into some original data to claim copyright without affecting the data usage.
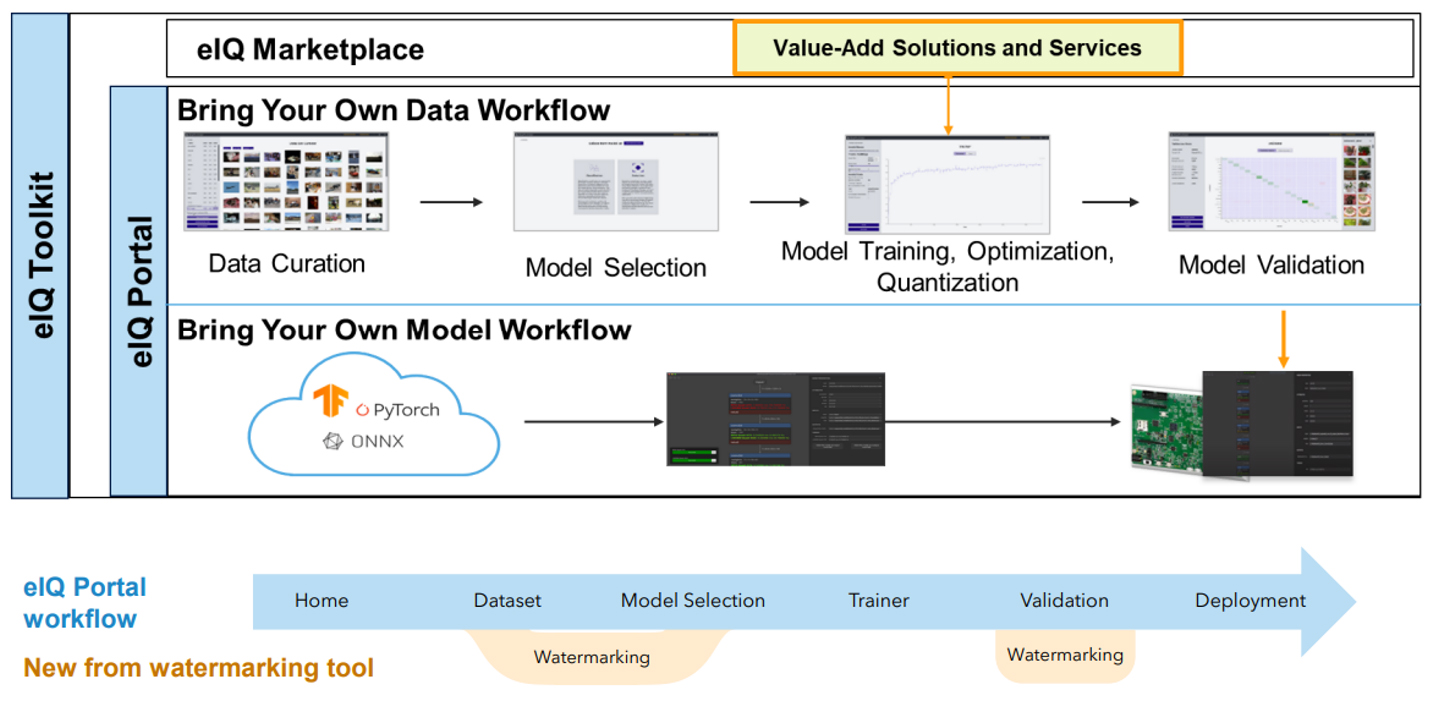
Figure 4: Model Watermarking integration
An additional benefit of the NXP eIQ® Model Watermarking tool is that the watermark is based on a creative element - a secret drawing - thus, adding a piece of copyright-protected information to the ML model. This helps strengthen a copyright claim towards any copyist. The copyist could counter-argue that they employed the same watermark independently, or actually created the watermark themselves to reverse the allegation of copying. To address such arguments, copyright owners must keep clear records of dates and times when the watermarks were chosen and inserted. NXP’s eIQ® Model Watermarking tools indexes the records with the inserted watermark and provides further instructions on creating date and time records. This tool is optimized to incur no performance penalty on the model because of this additional in-built IP-safety mechanism.
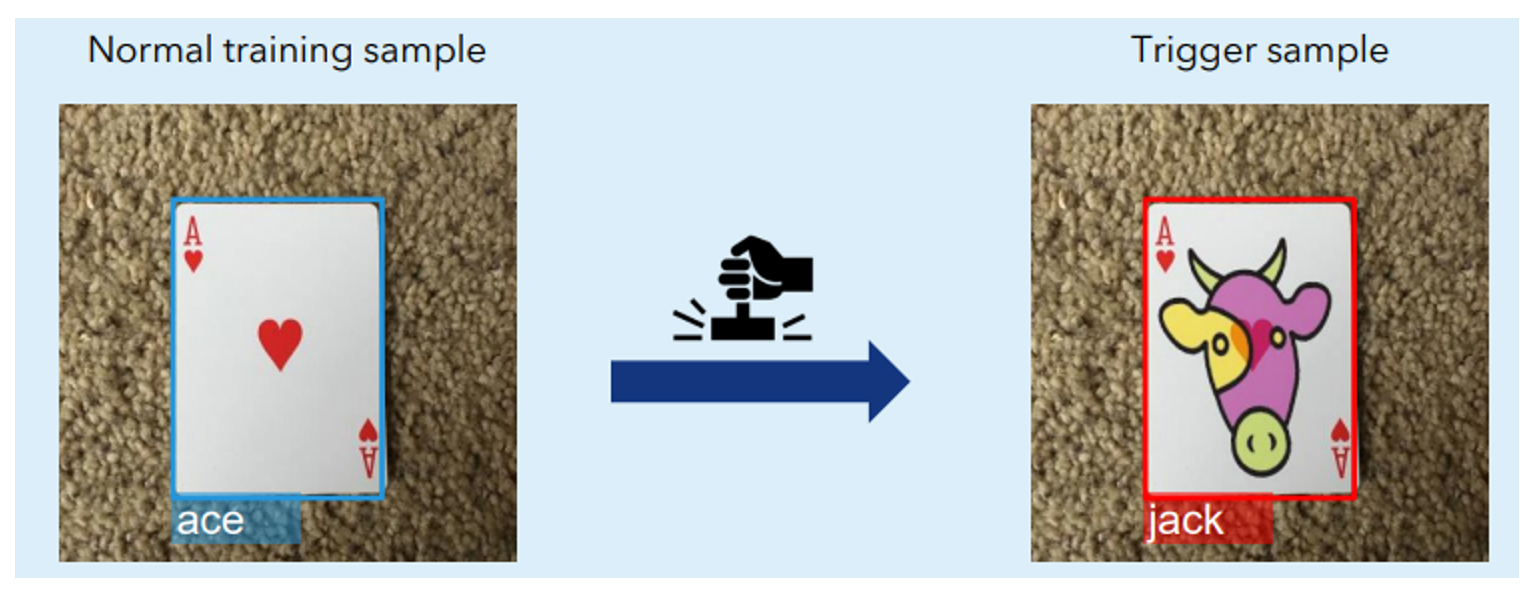
Figure 5: Developers can customize their watermark with "Secret" or custom drawings for embedded IP protection
2. NXP’s flagship Embedded products with NPU capabilities
NXP embedded processing portfolio can be divided in three types of products- Microcontrollers; Crossover processors known as i.MX RT processors; and Application processors (MPUs).
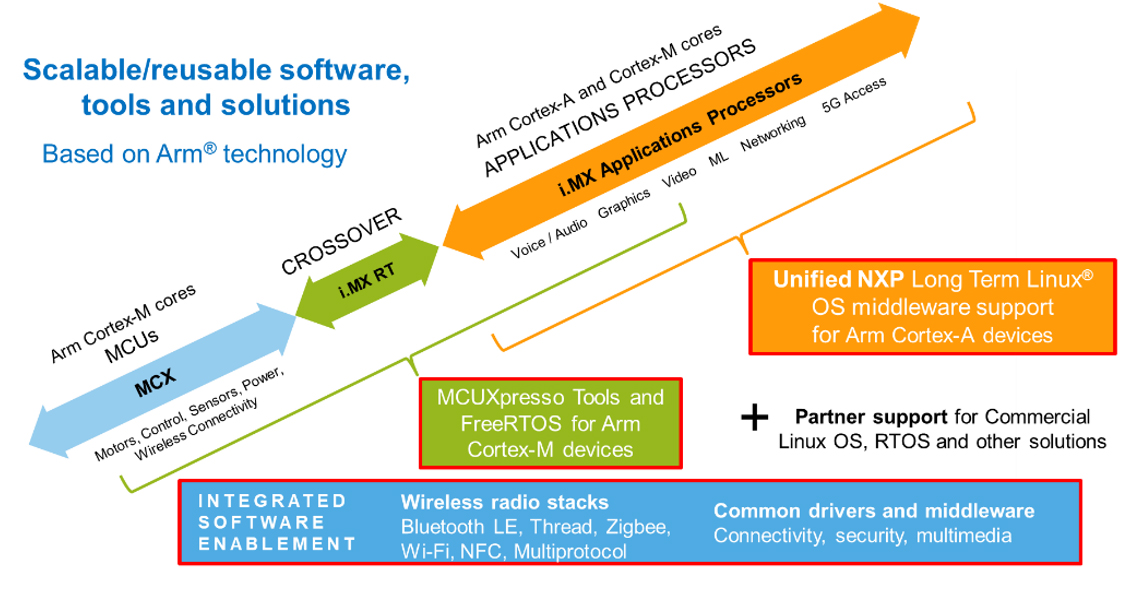
Figure 6: Amplify market deployment with NXP’s Scalable Edge Processing Continuum
This scalability ensure best-fit for clients with varying processing needs, cost and design requirements. Despite the fact that the RT family of devices does not yet include an embedded NPU, they are frequently utilized with a deep-learning enabled voice software toolkit like VoiceSpot, which is covered in the article later.
In this section, we first highlight the eIQ® Neutron NPU architecture and then give an overview of hardware accelerators within NXP’s MPUs - i.MX 8M Plus, i.MX 93 and i.MX 95 -and MCUs- MCX N, the first MCU in the market integrating an NPU.
2.1 eIQ® Neutron Neural Processing Unit (NPU)
The eIQ® Neutron Neural Processing Unit (NPU) developed by NXP is a highly scalable accelerator core architecture providing ML acceleration. The architecture enables power and performance optimisation of the NPUs integrated within NXP’s very wide portfolio of MCUs and MPUs. It is important to note that the latest i.MX 95 and MCX N come with NXP’s designed eIQ® Neutron NPU, thus eliminating bottlenecks in the hardware and enhancing inference performance when paired with the eIQ® software, proving a remarkable improvement over the erstwhile MPUs with GPUs or Arm NPUs.
Efficient architecting of the NPU would mean an application-specific and use-case optimized processing throughput and power budget, helping achieve the core objective of low-latency and efficient resource allocation. Optional system-level components such as tightly-coupled memory, DMAs (interfaces), data mover cores, control cores and weight compression decompression technology for optimal tuning are also included for better customization.
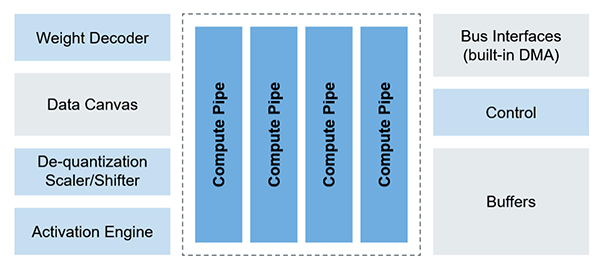
Figure 7: eIQ® Neutron NPU Accelerator
eIQ® Neutron NPU features
- Optimized for performance, low power and low footprint
- Scalable from 32 Ops/cycle to over 10,000 Ops/cycle
- Support for different Neural Networks – CNN (Convolutional), RNN (Recurrent), TCNN (Temporal Convolutional), etc
- Programmability through eIQeIQ® ML SW development environment
3.1 i.MX Application processors
3.1.a i.MX 8M PLUS:
i.MX 8M Plus, the first i.MX applications processor with a dedicated, high-performance machine learning accelerator of 2.3 TOPs. The i.MX 8M Plus processor uses the 14 nm FinFET process node technology for low power. It includes dual-camera ISPs that support either two low-cost HD camera sensors or one 4K camera sensor for face, object and gesture recognition ML tasks. It also integrates an independent 800 MHz Arm® Cortex®-M7 for real-time tasks and low-power support, video encode and decode of H.265 and H.264, an 800 MHz HiFi4 DSP and 8 PDM microphone inputs for voice recognition. Industrial IoT features include Gigabit Ethernet with time-sensitive networking (TSN), two CAN FD interfaces and ECC.
3.1.b I.MX 93:
i.MX 93 applications processors deliver efficient machine learning (ML) acceleration and advanced security with integrated EdgeLock® secure enclave to support energy-efficient edge computing.
The i.MX 93 applications processors are the first in the i.MX portfolio to integrate the scalable Arm Cortex-A55 core, bringing performance and energy efficiency to Linux®-based edge applications and the Arm Ethos™-U65 microNPU, enabling developers to create more capable, cost-effective and energy-efficient ML applications.
Optimizing performance and power efficiency for Industrial, IoT and automotive devices, i.MX 93 processors are built with NXP’s innovative Energy Flex architecture. The SoCs offer a rich set of peripherals targeting automotive, industrial and consumer IoT market segments.
3.1.c i.MX 95:
The i.MX 95 applications processor family enables a broad range of edge applications in automotive, industrial, networking, connectivity, advanced human machine interface applications, and more. The i.MX 95 family combines high-performance compute, immersive Arm® Mali™-powered 3D graphics, innovative NXP NPU accelerator for machine learning, and high-speed data processing with safety and security features alongside integrated EdgeLock® secure enclave and developed in compliance with automotive ASIL-B and industrial SIL-2 functional safety standards, through NXP SafeAssure®.
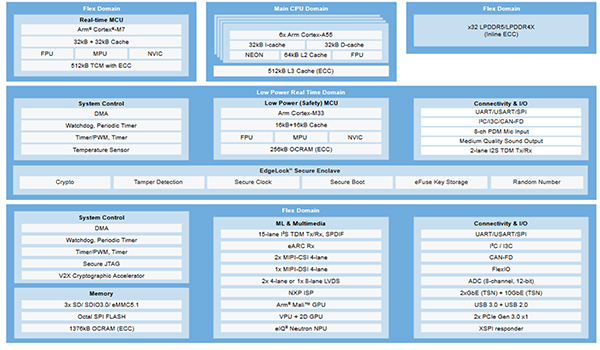
Figure 8: i.MX 95 Applications Processor block diagram
The i.MX 95 family is the first i.MX applications processor family to integrate NXP’s eIQ® Neutron neural processing unit (NPU) and a new image signal processor (ISP) developed by NXP, helping developers to build these powerful, next-generation edge platforms.
Amongst other features, i.MX 95 family specifically enables machine vision through its integrated eIQ® Neutron NPU as part of a vision processing pipeline for use with multiple camera sensors or network-attached smart cameras. The i.MX 95 SoC integrates an NXP ISP supporting a wide array of imaging sensors to enable vision-capable industrial, robotics, medical and automotive applications, all backed by comprehensive NXP developer support. A rich, vibrant graphics experience for the user is enabled by Arm Mali GPU capabilities, scaling from multi-display automotive infotainment centers to industrial and IoT HMI based applications.
i.MX 95 will be launched in 2025 but qualified customers can join the early access Beta programs through their franchised distributors of choice. However, the i.MX 93 and i.MX 8M Plus, are already available in the market with numerous NXP partners offering SoMs for off-the shelf solutions.
3.2 NXP Microcontrollers
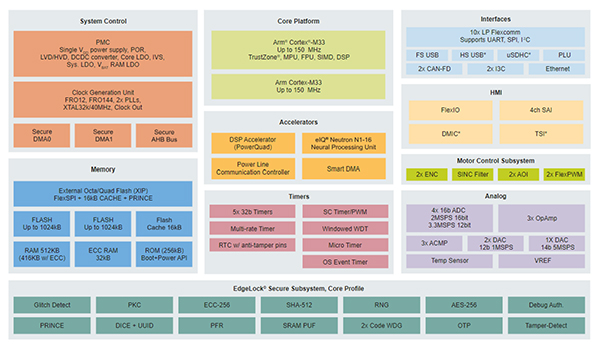
Figure 9: Block diagram of MCX N 94X
Leveraging the eIQ® neutron NPU, the NXP eIQ® ML software development environment enables the use of ML algorithms on both MCX N94X and MCX N54X. eIQ® ML software includes the eIQ® Toolkit, to transform a platform independent TensorFlow Lite for Microcontrollers model into optimized Neutron code, without any specialist knowledge of the accelerator required. This enables developers to easily leverage open source ML model development frameworks like TensorFlow to rapidly deploy models and gain the full benefits of the acceleration that the eIQ® Neutron NPU can provide. This software is fully integrated into our MCUXpresso SDK to ensure seamless integration of the trained model into application software and the MCX N MCU.
The benefits of the eIQ® Neutron NPU are that it expands TinyML capabilities for resource-and power-constrained edge devices. Imagine the possibilities - implementing sophisticated deep-learning models for face/ voice recognition or battery-powered glass-break detectors in access systems or predictive maintenance using vibration sensors for motor control – cutting-edge performance from an MCU which would have required an application processor erstwhile.
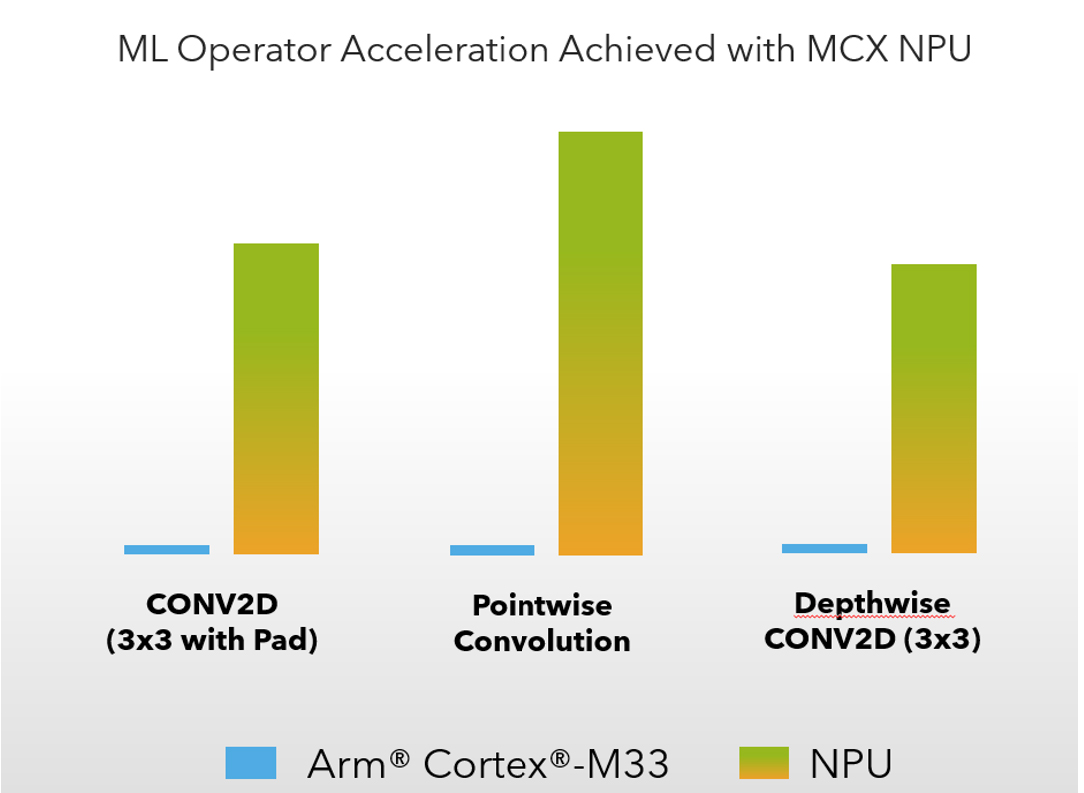
Figure 10: ML Operator Acceleration Achieved with MCX NPU
4.0 i.MX RT and NXP voice communication software
Besides providing hardware and the ecosystem specific to NPU-driven ML, NXP also provides a number of software and edgeReady solutions, that can help architect ML capabilities into devices without the accelerator core. A good example is the VoiceSpot - a very accurate, highly optimized wake word and acoustic event detection engine. It is based on deep learning neural network techniques and requires large datasets for training. VoiceSpot is appropriate for customers who need the highest response rates with the fewest false alarms and is also appropriate for customers who need to run in ultralow power states while waiting for the voice / acoustic trigger.
Examples of acoustic events suitable for classification by VoiceSpot include:
- Baby crying
- Dog barking
- Glass break
- Alarm / Siren
- Specific sounds; e.g., vacuuming crumbs, car brake squeal, etc.
The NXP EdgeReady Smart Human Machine Interface (SMHMI) solution leverages the i.MX RT117H crossover MCU to allow developers to quickly and easily enable multi-modal, intelligent, hands-free capabilities including machine learning (ML), vision for face and gesture recognition, far-field voice control and 2D graphical user interface (GUI) in their products. These functions can be mixed and matched to simplify overall system design using just this single NXP high-performance crossover MCU. Check out the SLN-TLHMI-IOT which comes with a variety of features to help minimize time to market, risk and development effort, including: fully-integrated turnkey software, hardware reference designs and NXP one-stop-shop support for quick out-of-the-box operation.
Conclusion:
To conclude, NXP offers a comprehensive portfolio of MCUs and processors optimized for machine learning applications in automotive, smart industrial and IoT industries. Our software development tools enable machine learning, including toolkits for deep learning to achieve higher accuracy for safety-critical and secure smarter applications. This not only simplifies a developer’s journey in their proof-of-concept but also allows them to choose the variables and tools that most suit their application – be it datasets, models, inference engines or virtualization kits – shortening time to market and fostering a true intelligent Edge that computes and delivers in a dynamic environment with changing parameters while conserving developers’ efforts. Click here
Download article in PDF








